Статистические методы анализа лексики
Одной из
наиболее важных характеристик лексики является то, что она представляет собой статистически организованную структуру. Вероятностные характеристики слова
проявляются в неодинаковой частотности их в речи, в многообразных видах
лексических связей, обычно разных по
своей силе (по интенсивности проявления). Между частотой слова в речи (тексте) и его порядковым номером расположения (рангом) в частотном словаре
существует статистическая
зависимость, выражаемая формулой Ципфа 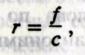 где г — ранг слова в частотном словаре; / — частотность слова в тексте; с —
постоянная величина. На основании закономерности, выражаемой этой формулой,
устанавливается статистическая структура текстов на естественном языке,
определяется зависимость между длиной текста и объемом словника, мера
покрываемости текста самыми частыми
словами и т. д. (Фрумкина 1964).
где г — ранг слова в частотном словаре; / — частотность слова в тексте; с —
постоянная величина. На основании закономерности, выражаемой этой формулой,
устанавливается статистическая структура текстов на естественном языке,
определяется зависимость между длиной текста и объемом словника, мера
покрываемости текста самыми частыми
словами и т. д. (Фрумкина 1964).
Данные о статистическом распределении слов в языке фиксируются в частотных словарях, которые созданы для многих языков, в том числе для русского и белорусского.
Между частотными и содержательными характеристиками лексических единиц существует закономерная связь. Установлено, например, что самые частотные слова в естественном языке, как правило, являются наиболее краткими, наиболее древними, наиболее простыми по морфологической структуре, наиболее многозначными (см. об этом: Общее языкознание 1976: 44—63).
Статистические методы все шире используются для изучения характера семантических связей между словами. Так, например, установлено, что слова, часто встречающиеся вместе в определенном отрезке текста, теснее связаны между собой по смыслу, чем слова, реже появляющиеся рядом в этом же отрезке текста. Эта особенность позволяет объективно измерять степень связи слов по тем их семантическим свойствам, которые реализуются при употреблении слов в текстах, и тем самым вскрывать устройство лексической системы без обращения к системности экстралингвистических реалий, которые обозначены рассматриваемыми словами.
Статистические методы помогают вскрыть закономерности распределения лексических единиц как массового явления и установить, случайный или неслучайный характер носят эти распределения. С помощью количественных методов устанавливается абсолютная частога фиксируемых лексических единиц в интересующих нас текстах; в свою очередь, частотой характеризуются вероятностные свойства слов как языковых единиц.
Количественные и статистические методы достаточно широко используются в сочетании с описательными, психолингвистическими и другими методами, поскольку часто качественные различия между словами носят не строго логический характер, а представлены в виде неодинаковой интенсивности (степени проявления данного качества), что наиболее точно можно выразить с помощью количественных показателей. Установление частотных характеристик слова имеет, например, немаловажное значение при создании учебников тех или иных языков, ибо известно, что 1000 самых частых слов любого языка покрывает до 85 % текстов, написанных на этом языке. Естественно, что такие самые частые слова должны включаться в учебники в первую очередь.
Количественные данные могут быть использованы в качестве критерия для выбора нормы в случаях существования в языке нескольких вариантов употребления того или иного лексического явления. При этом очевидно, что более часто используемые варианты предпочтительнее для рекомендации в качестве нормы. С помощью количественного анализа лексики можно дифференцировать литературные тексты с точки зрения их содержания (Головин 1971).
Одежда, обувь, игрушки, товары для детей - отзывы о нас не врут lego star wars kinderly.ru